

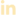

 Curso Full Cycle 4.0
Curso Full Cycle 4.0  Curso Full Cycle 4.0 Juniors
Curso Full Cycle 4.0 Juniors  MBA em Engenharia de Software com IA
MBA em Engenharia de Software com IA  MBA Arquitetura Full Cycle
MBA Arquitetura Full Cycle  Pós Liderança Técnica
Pós Liderança Técnica  Pós GO Expert
Pós GO Expert  Devops Pro
Devops Pro 
O Apache Kafka é uma plataforma de streaming distribuída. Portanto, de forma distribuída, ele consegue processar uma grande quantidade de dados e entregá-los em tempo real aos seus consumidores.
Características do Apache Kafka
O Kafka é uma plataforma unificada, de alta capacidade e baixa latência para tratamento de dados em tempo real e trabalha de forma distribuída. Ou seja, conseguimos colocar diversas máquinas e nodes como se estivessem em uma sinfonia, falando a mesma língua, sabendo que os dados serão armazenados e distribuídos entre esses nodes.
O Kafka também é um banco de dados. Portanto, todos os dados que entram ficam armazenados, sendo possível o monitoramento real-time, porém, eventualmente poderemos consultar novamente as informações. Há uma série de parâmetros e regras para, por exemplo, especificar quanto tempo esses dados ficam armazenados e etc.
Uma outra característica muito importante é a sua rapidez e baixa latência. Diferente de outros sistemas, o Kafka utiliza o disco para processar os dados e não a memória, porém, através de uma forma inteligente, seu processo de I/O consegue garantir uma super velocidade.
Há três pilares importantíssimos, de acordo com a página oficial do Kafka:
- Padrão Publish/Subscribe, semelhantes a uma fila de mensagens, onde os sistemas interessados entram em um canal de comunicação e tem acesso as informações publicadas em tempo real.
- Armazena fluxos de registros de maneira durável e tolerante a falhas.
- Processa fluxos de registros conforme eles ocorrem.
Conceitos Básicos
Producer, Consumer e Topic.
O Producer, basicamente irá produzir os dados a serem enviados ao Consumer.
O Consumer é quem recebe as informações.
O Topic é um streaming de dados, ou seja, são os dados transmitidos.
Vamos nos aprofundar nesse tema?
O que é um Topic?
Conforme falamos anteriormente, um Topic é o local aonde teremos um streaming de dados, que por sua vez, acaba atuando como um banco de dados. Por exemplo, quando um Topic recebe um dado do Producer, esse dado além de enviado, fica armazenado para eventuais consultas. Portanto, esse dado não se perde.
É muito importante explicar que um Topic possui diversas partições e cada uma dessas partições recebe um número. Exemplo: partição 0, 1, 2…
Quando criamos um Topic, obrigatoriamente deveremos definir o número de partições.
Vamos imaginar que temos um Topic “x” com três partições e toda vez que recebemos um dado nesse Topic ele irá armazenar o dado em uma partição. Isso ocorre de forma aleatória, pois o Kafka tem uma regra onde distribui esses dados para as partições.
Cada partição é uma sequência imutável e ordenada de registros que é continuamente anexada a um log de confirmação estruturado. Cada registro nas partições recebe um número de identificação sequencial chamado offset que identifica exclusivamente cada registro na partição. Ou seja, esses número que observamos na imagem acima, na partição 0, por exemplo, que vai de 0 até o 12. Vamos imaginar que esse offset seja como uma porta, um array. Toda vez que geramos um dado é criado um offset e os dados serão guardados nesse offset.
As informações são guardadas nesses offsets, ordenadamente, das mais antigas para as mais novas.
Para que serve uma partição?
Essa é uma pergunta bem comum. Vamos explicar detalhadamente.
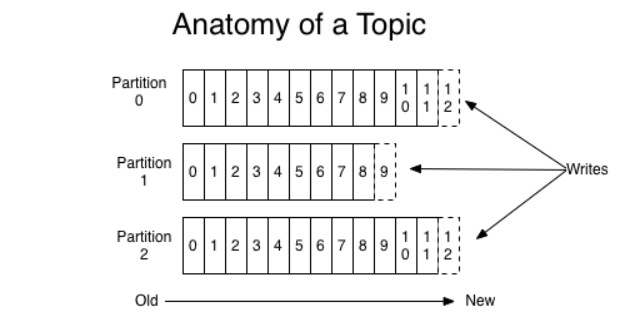
Observe a imagem:
Temos um Topic e nesse topic temos o Producer. O producer escreve as informações, gerando um offset para cada informação, que por sua vez, podem ser acessados pelo Consumer. Note que é possível termos diversos consumers nesse topic, e cada consumer pode ler um offset diferente em um mesmo topic.
Aplicações do Apache Kafka
Para quê o Kafka funciona e para que ele serve?
Como exemplo, podemos citar um processo de desenvolvimento que participamos: A bola inteligente.

Nossa equipe desenvolveu uma tecnologia que consistia em ter os dados em tempo real da posição da bola em determinadas situações de um jogo de vôlei: a bola caiu dentro (antes da linha), caiu fora (depois da linha)?
Desenvolvemos esse projeto em C++, sendo que colocamos um chip no interior da bola de vôlei e com algumas antenas instaladas na quadra, recebíamos essas informações em tempo real. Naquela época desenvolvemos um sistema para receber essas informações do zero. Hoje em dia, poderíamos sem problema algum termos utilizado o Kafka para receber essas informações.

Uma curiosidade sobre esse projeto: com aproximadamente 16 antenas instaladas na quadra, recebíamos cerca de 1600 posições da bola por segundo. Ou seja, um número enorme de informações.
Ficamos sabendo que um grande app de transporte utiliza esse sistema de mensagens. Ou seja, ele usa Kafka para pegar a posição onde os motoristas e passageiros estão em tempo real. Perceba que quando falamos do Kafka, não estamos falando somente de uma fila de informações entre APIs e microsserviços, ele é muito maior que isso.
No Apache Kafka os dados gravados podem ser acessados por um outro consumidor ou mesmo serem processados novamente, dessa forma, pegar dados estatísticos para conseguir, inclusive, estimular e melhorar o software, melhorar a inteligência do software, treinar uma rede neural ou algo desse tipo.
Kafka Cluster
Um cluster de Kafka é basicamente um conjunto de brokers. Esses brokers, de uma forma mais simples, podem ser chamados de intermediários ou facilitadores. Cada broker é responsável por armazenar os dados de uma partição. Ou seja, cada broker é um server.
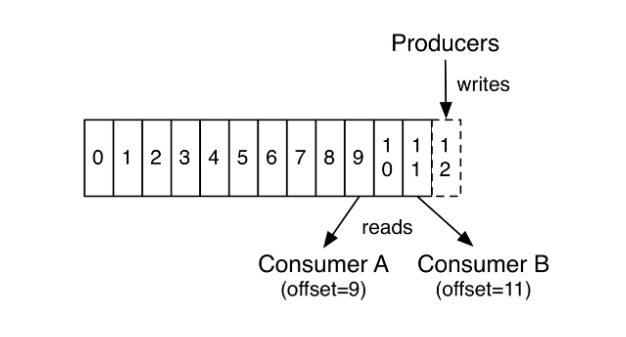
Quando temos um Topic, nem sempre as partições desse Topic estão em uma mesma máquina e isso torna o Kafka extremamente eficiente, pois ela distribui essas partições entre os brokers.
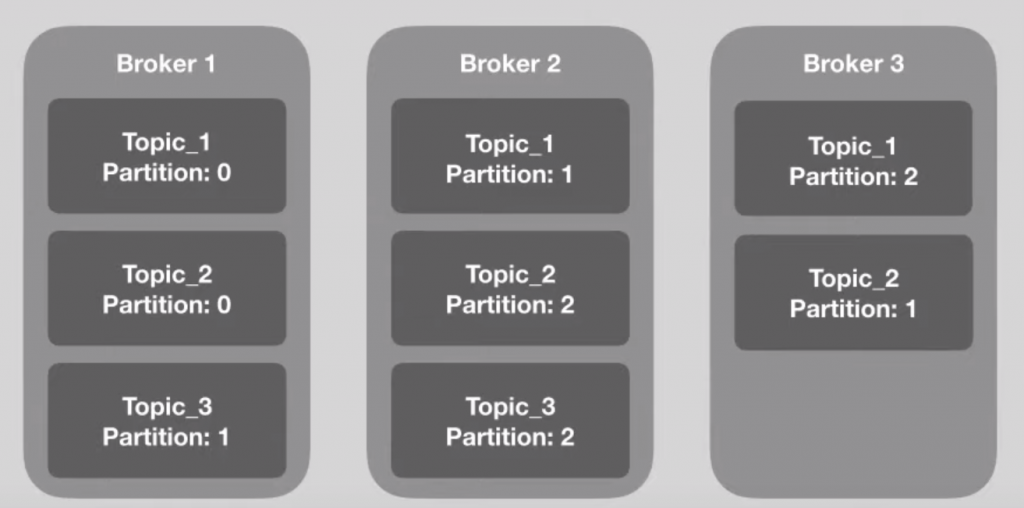
Na imagem acima, ilustramos esse processo de distribuição de partições entre os brokers. Note que não há uma ordem pré determinada de qual partição será alocada para os brokers. O Apache Kafka faz isso de forma automática, independente de ação do usuário.
Replication Factor
E o que aconteceria se, em algum momento em que estivéssemos consumindo alguma informação, um de nossos brokers saísse do ar? Perderíamos todas as informações?
O Kafka, justamente por trabalhar de forma distribuída, possui um recurso excelente chamado de Replication Factor. Ou seja, ele consegue replicar a informação de uma partição em brokers diferentes.
Como exemplo, vamos supor que temos três brokers, conforme a imagem à seguir:
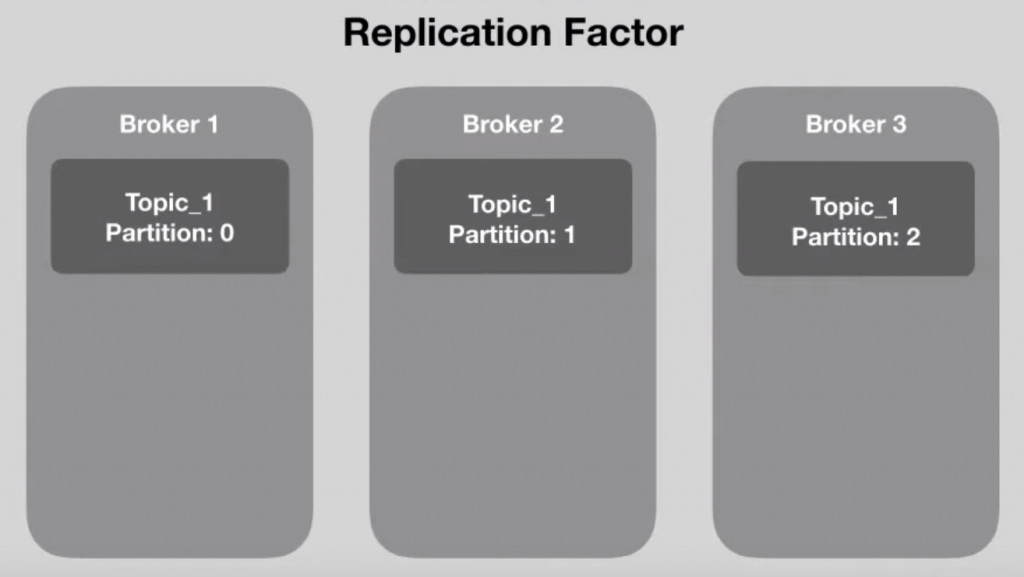
Imagine que estamos consumindo a informação que está no Topic 1, na partição 0 e esse broker simplesmente sai do ar. Como o Kafka irá se comportar?
Para evitar a perda das informações, quando é criada uma partição, o Kafka determina de forma automática quem vai ser o broker líder daquela partição.
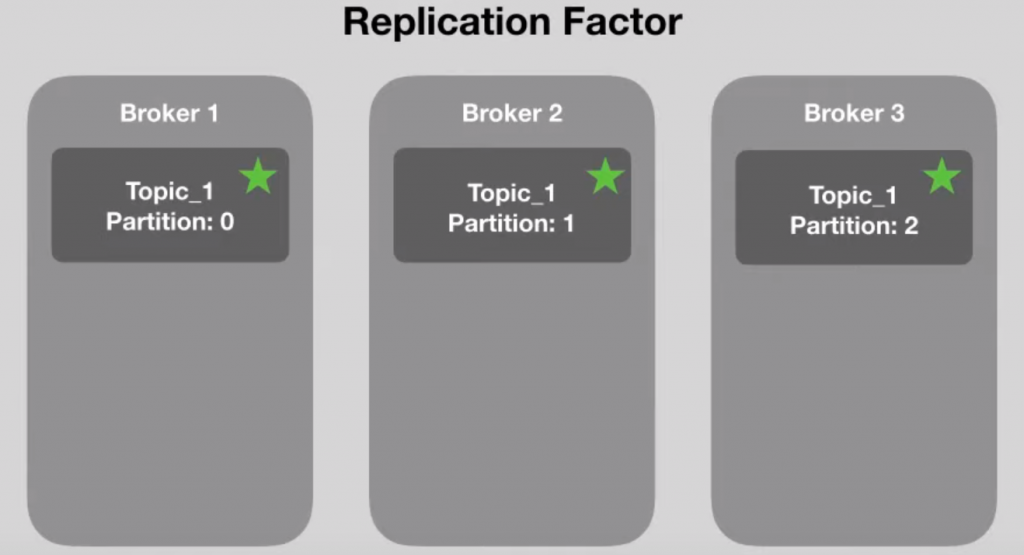
Cada partição é replicada em um broker líder.
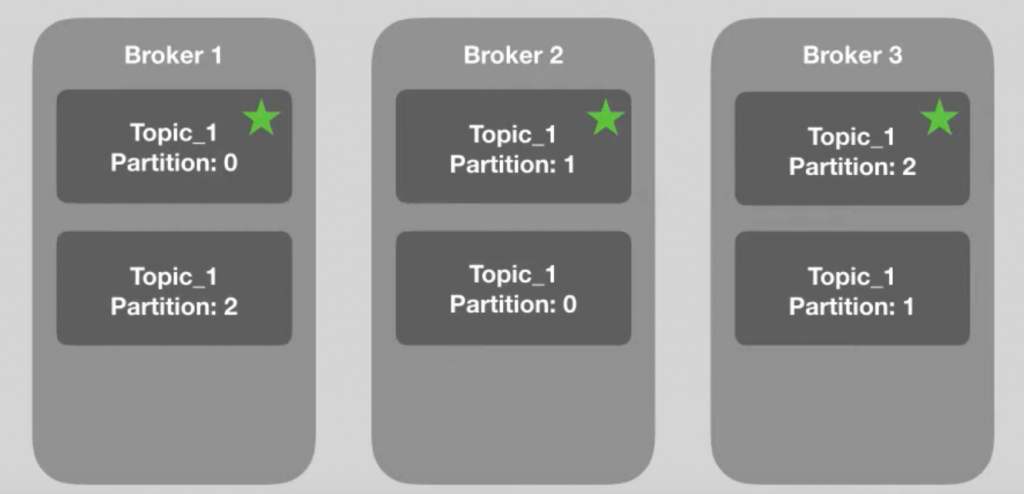
Dessa forma, portanto, se um broker cair, as informações da partição estarão salvas. Note que o broker 1 caiu, porém, as informações da partição 0 estão salvas no broker 2 e daí por diante.
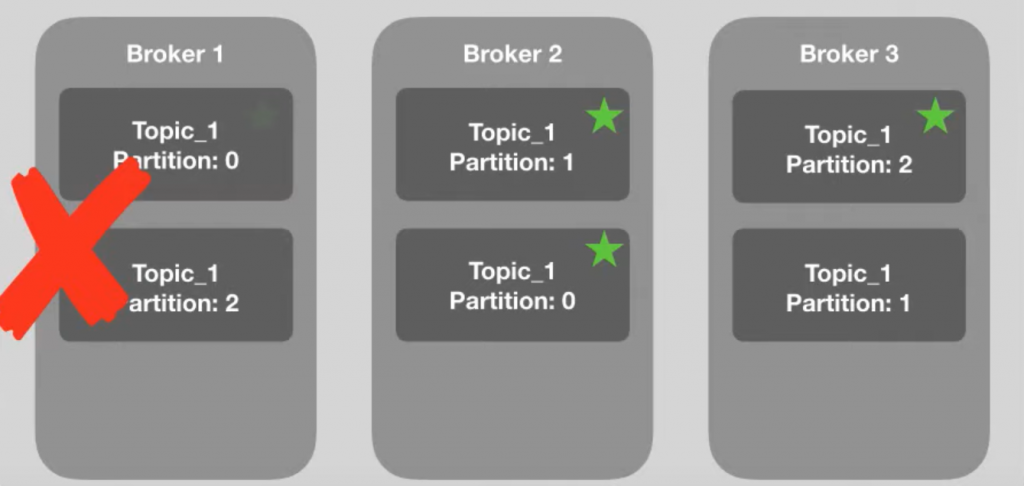
Note que o broker 2 assumiu como líder a partição replicada, já que o broker original está fora do ar.
O Kafka realiza esse balanceamento de brokers e partições, designando os líderes e partições utilizando a ferramenta Apache Zookeeper.
Consumer Group
Conforme já explicamos, temos o producer que grava e envia as informações para os brokers e, por sua vez, esses brokers são ordenados e guardam essas informações gerando os offsets e, por fim, temos os consumers, que por sua vez, leem essas informações.
O Kafka ordena esses consumers em grupos, chamados de Consumer Groups. E qual a finalidade do Consumer Groups?
Basicamente, as informações de uma partição podem ser lidas por somente um consumer este alocado em um consumer group. Ao mesmo tempo, você pode ter diversos consumers dentro de um mesmo grupo, organizando-se entre si para definir qual consumir lerá determinada partição.
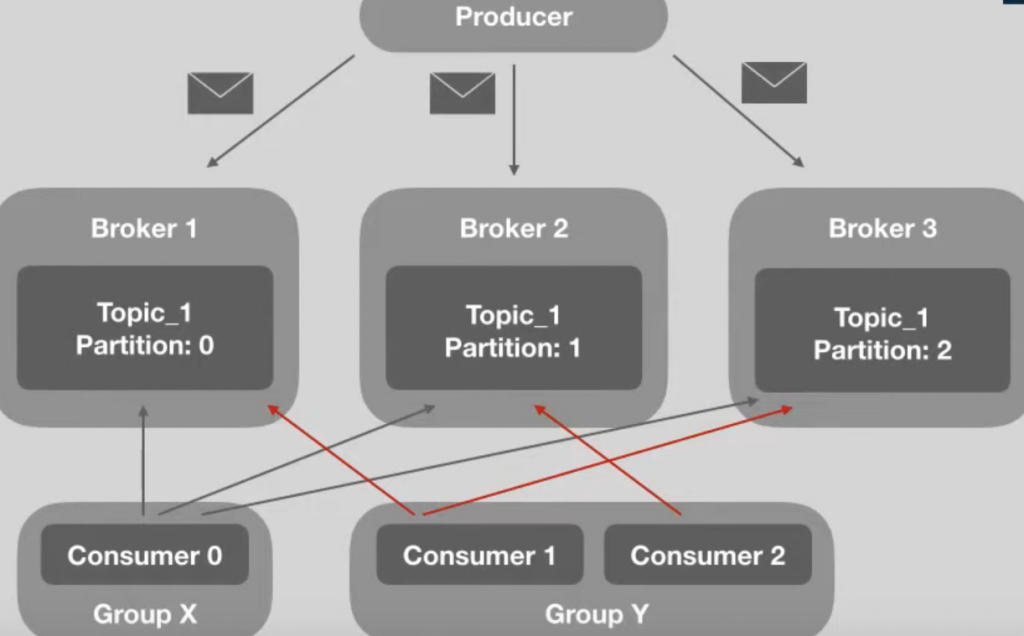
Note que o consumer 0, alocado no group X está sozinho, portanto esse consumer poderá ler as informações dos brokers 1, 2 e 3. Entretanto, no group Y, podemos verificar que o Consumer 1 lê as informações do broker 1 e 3, enquanto o consumer 2 lê as informações do broker 2.
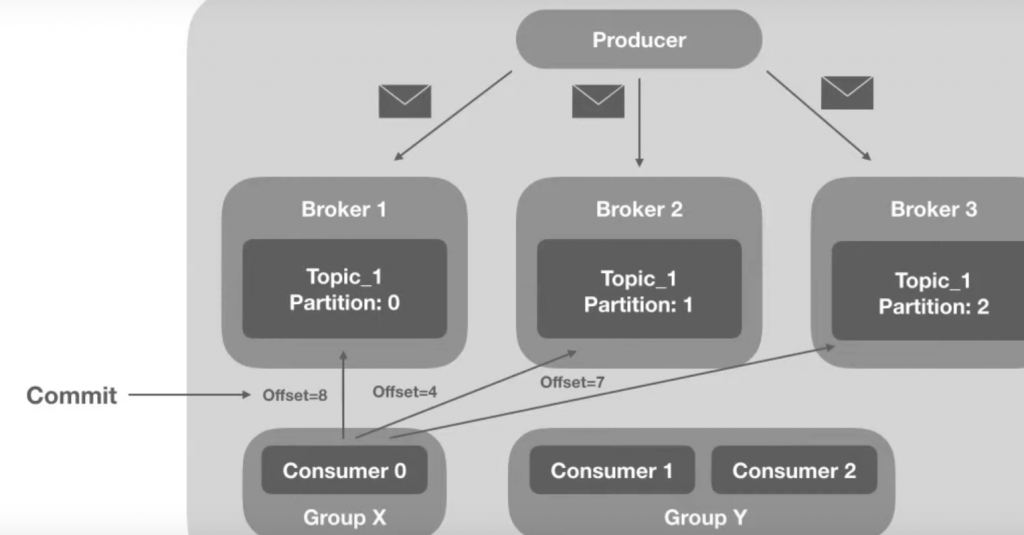
Toda vez que um consumer acessa um offset, é realizado um Commit, dessa forma, caso um consumer caia é possível saber quais informações foram vistas por ele.
Chegamos ao fim da nossa parte teórica. Quel tal iniciarmos a prática? Assista o vídeo e mãos a obra.
Assista Jornada Microsserviços, aposto que vai transformar sua carreira. Clique aqui.
Fontes:
https://kafka.apache.org/intro
Se você curtiu esse conteúdo e quer aprender mais sobre Apache Kafka, solicite contato clicando aqui e nós te ajudamos.